プロンプト/ prompt
18件の記事 / ページ 1 / 1
プロンプト・実用Tips

コンテキスト圧縮、6つのAIエージェントは何を守り何を捨てるか
長いコンテキストをどう圧縮するか。Claude Code、Codex CLI、Cursor、Clineなど主要6エージェントの戦略を比較すると、「階層的プログレッシブ圧縮」への収束という共通点と、何を保護するかという根本的な相違点が浮かび上がる。
ブラウザ上でPython ASGIアプリを動かす:Service Worker+Pyodideの新手法
PyodideとService Workerを組み合わせ、ブラウザ上でPython ASGIアプリをネイティブに近い形で動作させる手法が登場した。従来のWeb Worker方式が抱えていたJavaScript非実行の制約を克服し、Datasette Liteの本格的なアップグレードへの道が開かれようとしている。

バイブコーダーへの報復:プロンプトインジェクションでデータ消去を仕込んだ開発者の事件
「バイブコーディング」に嫌気が差した開発者が、他者のコードにデータ消去を引き起こすプロンプトインジェクションを密かに埋め込んだとされる事件が話題を呼んでいる。AIコード生成への過信がセキュリティリスクに直結することを示す、象徴的な出来事だ。

TXT・Markdown・HTML——出力形式でLLMの品質はどう変わるか
プロンプトで指定する出力形式がLLMの品質・速度・トークン数に与える影響を、Qwen3.6 35B A3Bを使った実測データで比較した投稿が話題だ。Markdownが品質スコア78/100で首位。HTMLはトークン爆発と品質低下を招く結果となった。

AIエージェントの「なぜ」を可視化するOSS「Spice」——決定層という新概念
AIエージェントは「実行」が得意になった。だが「何をすべきか、なぜそれか」という上位の意思決定は依然として人間任せだ。その空白を埋めようとするOSSプロジェクト「Spice」が登場した。エージェントの推論境界を記録・可視化する「決定層」という設計思想を持つ。

ローカルLLMフロントエンド選びの現実:vim職人からOpen WebUIまで
ローカルLLMを動かすとき、フロントエンドの選択は思いのほか個人差が大きい。Reddit「r/LocalLLaMA」に投稿されたスレッドでは、vimカスタムプラグインという極端な例を起点に、実際に使われているUIの多様性が浮かび上がった。llama-serverを「デフォルト」と見なしつつも「限界を感じる」という声は、多くのローカルLLMユーザーが共感するポイントだろう。

Gemma 4 31Bの創作特化ファインチューン「Ortenzya」登場——自然な英語散文とRP品質を追求
Gemma 4 31B instructをベースに、創作文章・翻訳・ロールプレイ特化でファインチューンした「gemma-4-Ortenzya-The-Creative-Wordsmith-31B-it-uncensored-heretic」がリリースされた。SafetensorsとGGUF形式で提供され、ローカル環境での即時利用が可能だ。
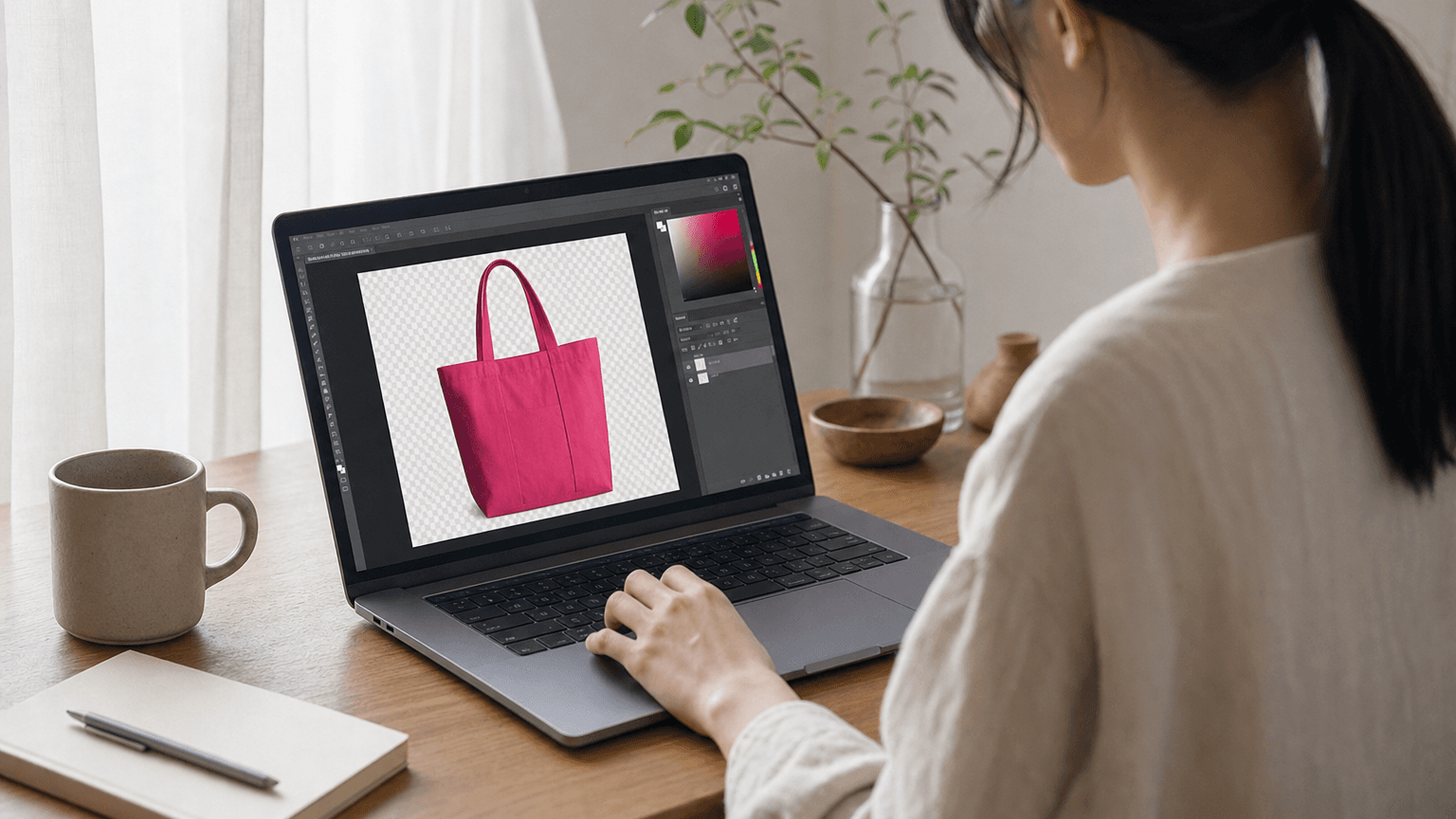
「背景を透明にして」の一言でChatGPT画像生成が変わる、魔法フレーズの正体
ChatGPTの画像生成に「背景は透過したいのでなし」と添えるだけで、切り抜き不要の透過PNG素材が一発で生成される。プロンプト1行の差が、デザイン工数を根本から変える。その仕組みと再現手順を分解する。

ローカルLLMに本物の金融データを——自己ホスト型MCPサーバー「Equibles」の設計思想
クラウド依存なし、APIキーなし。SEC開示書類・13F・議会取引・FREDマクロ指標をローカルLLMエージェントに直接供給するMCPサーバー「Equibles」がOSSとして公開された。プロンプト職人の視点から、このアーキテクチャが持つ意味を読み解く。

Claude Codeの使用量をデスクトップで可視化——オープンソースツール「Clawdmeter」登場
Claude Codeのトークン消費・コスト・セッション統計をリアルタイムでデスクトップに表示するオープンソースダッシュボード「Clawdmeter」が公開された。AIコーディングを日常的に使うパワーユーザーにとって、使用量の可視化は課金管理と生産性最適化の両面で直接的な意味を持つ。

CopilotKit(MIT):エージェントUIを横断する30kスターのオープンソース構成要素
エージェントアプリ開発のUI層で、ストリーミング・ツールコール描画・状態同期を個別に実装する苦痛は根深い。CopilotKitはMITライセンス・GitHubスター3万超のReactコンポーネント群で、その苦痛を一括して引き受ける。AG-UIという開放プロトコルにより、LangGraph・CrewAI・LlamaIndexなど主要フレームワーク全てに同一UIを接続できる。

8GBスマホでGemma 4 E2Bが動く——プライベート音声メモアプリの実装詳解
クラウド不要、アカウント不要。OnePlus CE 5(RAM 8GB)上でGemma 4 E2Bをローカル動作させ、音声メモの分類・リマインダー抽出まで完結させた実装報告が注目を集めている。2.4GBモデルがスマートフォン上でクリーンなJSON出力を返す——その事実が、エッジAIの現在地を示している。

会話中にリアルタイム学習するLLM永続メモリ「MDA」の実力と限界
すべてのLLM会話はゼロからスタートする。RAGはそれを補うが、今まさに進行中の会話から学ぶことはできない。その空白を埋めようとするのが「MDA(Memory-Driven Architecture)」だ。連想エンティティネットワークとOjaルールで会話中に記憶を更新し続けるこのシステムの構造と検証数値を読み解く。

SDRメール品質をどう計測するか:ベンチマーク設計の核心
AI生成のアウトバウンドメール(SDRスタイル)の品質評価は、返信率だけでは計測できない。単一指標への最適化が「クリックベイト」か「死んだ正確さ」を生む構造的矛盾がある。本稿では、その問題の解剖と、プロンプト設計者が取るべき評価フレームを整理する。

F2キー一発で仕事が速くなる。Windows時短ショートカット完全解説
キーボードとマウスの往復が、じわじわと作業時間を蝕む。1回数秒でも、1日100回積み重なれば数分のロスだ。Windowsには、その往復を断ち切るショートカットが揃っている。中でもF2は即効性が高い。本稿では、実務で使える時短キー操作を体系的に整理する。

llama.cppで特定フレーズを完全禁止するスクリプトが登場——出力制御の新手法
llama.cppの推論出力から任意のフレーズを禁止できるスクリプトがGitHubで公開された。モデルの重みを変えず、プロンプトも汚さず、ロジット操作で特定トークン列を封じる。ローカルLLM運用者にとって、出力品質と安全性を同時に担保する実用的な選択肢となりうる。

pip 26.1リリース:ロックファイルと依存関係クールダウンで開発環境が変わる
Pythonの標準パッケージマネージャー「pip」がバージョン26.1をリリース。待望のロックファイル機能(pylock.toml)と、新規パッケージの誤インストールを防ぐ「依存関係クールダウン」オプションが追加され、Python開発環境の再現性とセキュリティが大幅に向上する。

サーバー不要・完全ローカル!ChromeでGemma 4が動くAIエージェント拡張機能が登場
Hugging FaceのNico Martin氏が開発した「Transformers.js Gemma 4 Browser Assistant」がChrome Web Storeで無料公開された。WebGPUを活用しサーバー不要でブラウザ上でローカルAIエージェントを実行できる画期的な拡張機能だ。